InnoDB MVCC
1.什么是MVCC
MVCC(Multiversion Concurrency Control),中文全称叫中文全称叫多版本并发控制,是现代数据库(包括 MySQL、Oracle、PostgreSQL 等)引擎实现中常用的处理读写冲突的手段,目的在于提高数据库高并发场景下的吞吐性能。
如此一来不同的事务在并发过程中,SELECT 操作可以不加锁而是通过 MVCC 机制读取指定的版本历史记录,并通过一些手段保证保证读取的记录值符合事务所处的隔离级别,从而解决并发场景下的读写冲突。
下面举一个多版本读的例子,例如两个事务 A 和 B 按照如下顺序进行更新和读取操作
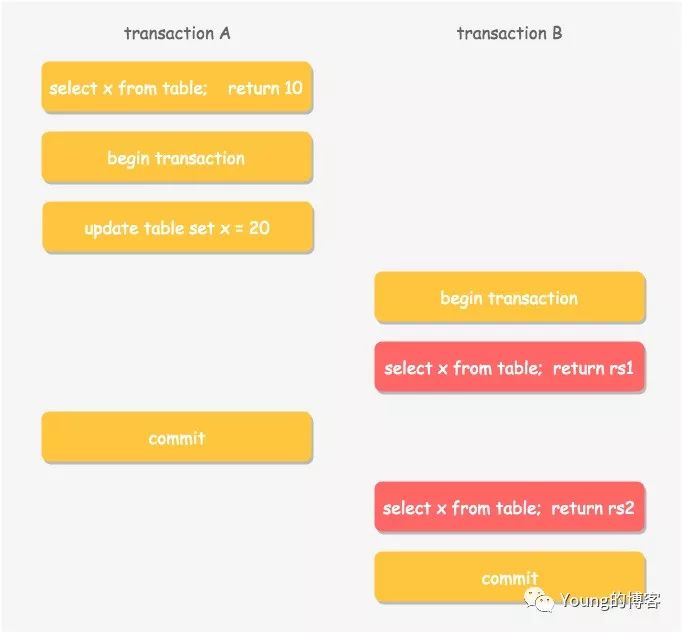
在事务 A 提交前后,事务 B 读取到的 x 的值是什么呢?答案是:事务 B 在不同的隔离级别下,读取到的值不一样。
- 如果事务 B 的隔离级别是读未提交(RU),那么两次读取均读取到 x 的最新值,即 20。
- 如果事务 B 的隔离级别是读已提交(RC),那么第一次读取到旧值 10,第二次因为事务 A 已经提交,则读取到新值 20。
- 如果事务 B 的隔离级别是可重复读或者串行(RR,S),则两次均读到旧值 10,不论事务 A 是否已经提交。
可见在不同的隔离级别下,数据库通过 MVCC 和隔离级别,让事务之间并行操作遵循了某种规则,来保证单个事务内前后数据的一致性。
2.为什么需要MVCC
InnoDB 相比 MyISAM 有两大特点,一是支持事务而是支持行级锁,事务的引入带来了一些新的挑战。相对于串行处理来说,并发事务处理能大大增加数据库资源的利用率,提高数据库系统的事务吞吐量,从而可以支持可以支持更多的用户。但并发事务处理也会带来一些问题,主要包括以下几种情况:
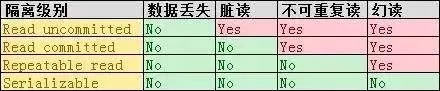
实现隔离机制的方法主要有两种:
- 加读写锁
- 一致性快照读,即 MVCC
3.InnoDB MVCC实现原理
InnoDB中MVCC的实现方式为:每一行记录都有两个隐藏列:DATA_TRX_ID,DATA_ROLL_PTR(如果没有主键,则还会多一个隐藏的主键列)。

DATA_TRX_ID
记录最近更新这条行记录的事务ID,大小为6个字节
DATA_ROLL_PTR
表示指向该回滚段(rollback segment)的 指针,大小为7个字节,InnoDB便是通过这个指针找到之前版本的数据,改行记录上所有旧版本,在undo中投通过链表形式组织。
DB_ROW_ID
行标识(隐藏单调自增id),大小为6字节,如果没有主键,InnoDB会自动生成一个隐藏主键,因此会出现这个列
。另外,每条记录的头信息(record header)里都有一个专门的bit(deleted_flag)来表示当前记录是否已经删除。
3.1 如何组织版本链
1 | 关于Redo log 和 Undo log的相关概念自行查找资料 |
上文提到,在多个事务并行操作某行数据的情况下,不同事务对该行数据的 UPDATE 会产生多个版本,然后通过回滚指针组织成一条 Undo Log 链,这节我们通过一个简单的例子来看一下 Undo Log 链是如何组织的,DATA_TRX_ID 和 DATA_ROLL_PTR 两个参数在其中又起到什么样的作用。
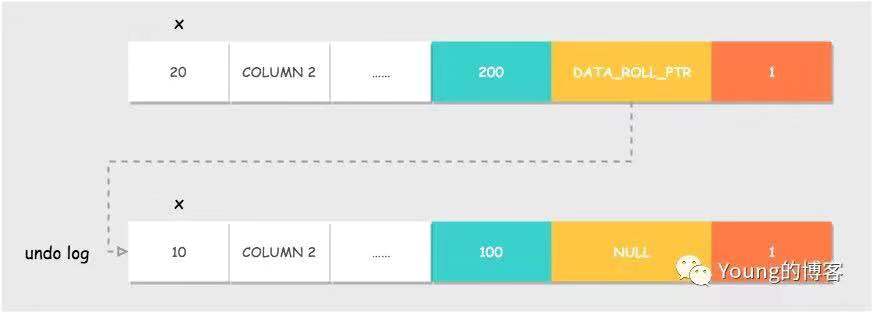
还是以上文 MVCC 的例子,事务 A 对值 x 进行更新之后,该行即产生一个新版本和旧版本。假设之前插入该行的事务 ID 为 100,事务 A 的 ID 为 200,该行的隐藏主键为 1。
事务A 的操作过程为:
- 对 DB_ROW_ID = 1 的这行记录加排他锁。
- 把该行原本的值拷贝到 undo log 中,DB_TRX_ID 和 DB_ROLL_PTR 都不动。
- 修改该行的值这时产生一个新版本,更新 DATA_TRX_ID 为修改记录的事务 ID,将 DATA_ROLL_PTR 指向刚刚拷贝到 undo log 链中的旧版本记录,这样就能通过 DB_ROLL_PTR 找到这条记录的历史版本。如果对同一行记录执行连续的 UPDATE,Undo Log 会组成一个链表,遍历这个链表可以看到这条记录的变迁。
- 记录redo log,包括undo log中的修改。
那么 INSERT 和 DELETE 会怎么做呢?其实相比 UPDATE 这二者很简单,INSERT 会产生一条新纪录,它的 DATA_TRX_ID 为当前插入记录的事务 ID;DELETE 某条记录时可看成是一种特殊的 UPDATE,其实是软删,真正执行删除操作会在 commit 时,DATA_TRX_ID 则记录下删除该记录的事务 ID。
3.2 如何实现一致性读 ReadView
在 RU 隔离级别下,直接读取版本的最新记录就 OK,对于 SERIALIZABLE 隔离级别,则是通过加锁互斥来访问数据,因此不需要 MVCC 的帮助。因此 MVCC 运行在 RC 和 RR这两个隔离级别下,当 InnoDB 隔离级别设置为二者其一时,在 SELECT 数据时就会用到版本链
核心问题是版本链中哪些版本对当前事务可见?
InnoDB 为了解决这个问题,设计了 ReadView(可读视图)的概念。
3.3 RR下ReadView的生成
在RR隔离级别下,每个事务touch first read时(本质上就是执行第一个 SELECT语句时,后续所有的 SELECT 都是复用这个 ReadView,其它 update, delete, insert 语句和一致性读 snapshot 的建立没有关系),会将当前系统中的所有的活跃事务拷贝到一个列表生成ReadView。
4.举个例子
数据表user
加入隐藏列

假如有两个事务开启
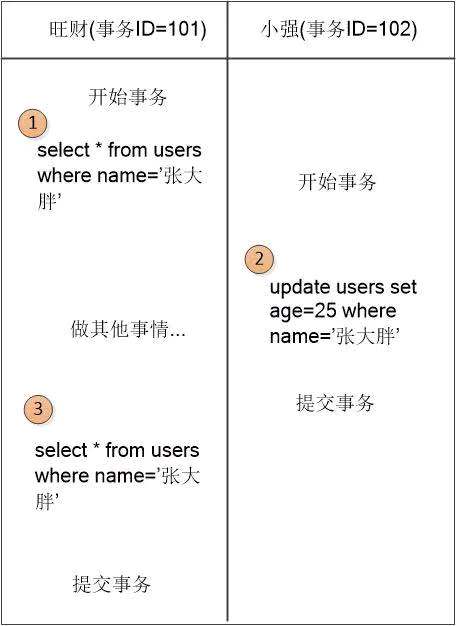
在1处时,数据是这样的:
于此同时,需要建立一个Read View的数据结构,它有三个部分:
- 当前活跃的事务列表[101,102]
- Tmin,就是活跃事务的最小值, 在这里 Tmin = 101
- Tmax, 是系统中最大事务ID(不管事务是否提交)加上1。 在这里例子中,Tmax = 103
在2的部分事务102做了修改,此时数据是这样的:

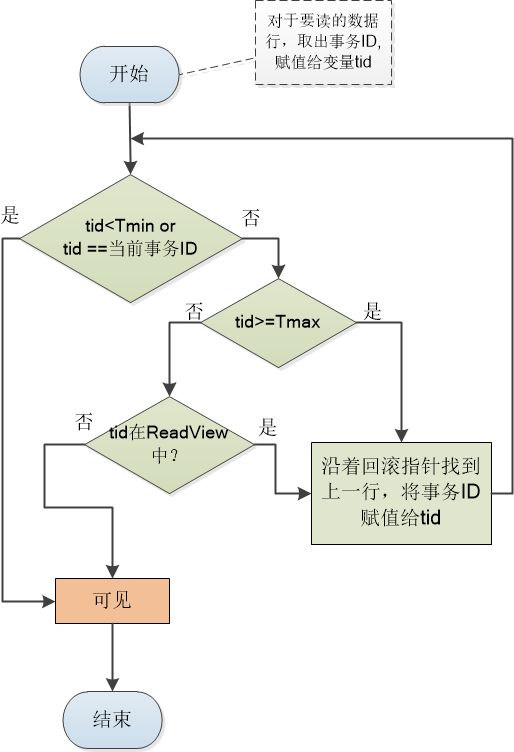
关键部分,下面的算法用来判断这些数据版本哪些是是对当前事务可见的
Read View结构
- 当前活跃的事务列表[101,102]
- Tmin,就是活跃事务的最小值, 在这里 Tmin = 101
- Tmax, 是系统中最大事务ID(不管事务是否提交)加上1。 在这里例子中,Tmax = 103
对于上述例子,第一次读取时:
- 取出要读取的数据,取出事务ID赋值给变量tid,tid=100。
- Tmin=101,tid<Tmin
- 可见
第二次读取时:
- tid=102
- Tmin=101,当前事务事务id=101,进入下个判断流程
- tid=102,Tmax=103,走入tid在ReadView中?
- tid=102在ReadView中,沿着回滚指针找到上一行,将事务id赋值给tid,tid=100
- 读取的数据和第一次相同
保证了可重复读
5.一个争议点
并非所有的情况都能套用MVCC读的判断流程,例如RR级别下
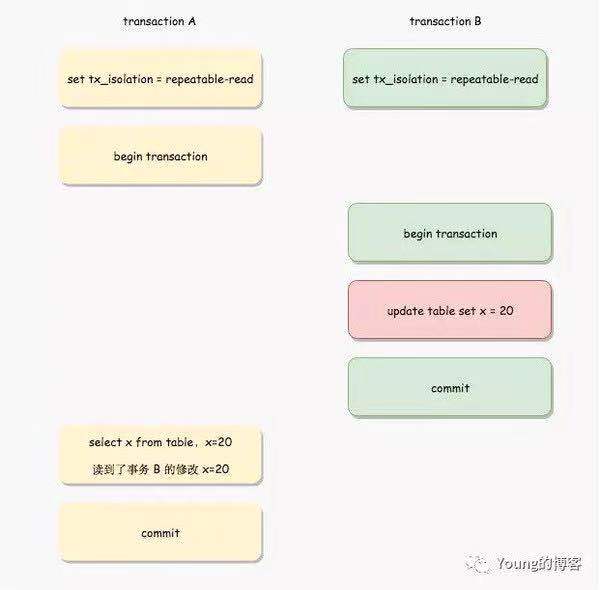
1.假设transaction A trx_id =200 ,transaction B trx_id =300,且事务B先于事务A提交,按照MVCC的判断流程,事务A生成的ReadView为[200],最新版本行记录DATA_TRX_ID=300,300比200大,照理不能访问,但是事务A实际上读到了事务B已经提交的修改。
6写在最后
RC、RR 两种隔离级别的事务在执行普通的读操作时,通过访问版本链的方法,使得事务间的读写操作得以并发执行,从而提升系统性能。RC、RR 这两个隔离级别的一个很大不同就是生成 ReadView 的时间点不同,RC 在每一次 SELECT 语句前都会生成一个 ReadView,事务期间会更新,因此在其他事务提交前后所得到的 m_ids 列表可能发生变化,使得先前不可见的版本后续又突然可见了。而 RR 只在事务的第一个 SELECT 语句时生成一个 ReadView,事务操作期间不更新。
]]>